
Data Products in DataHub: Everything You Need to Know


As the data landscape continues to rapidly transform, the concept of data products has emerged as pivotal to managing and leveraging data effectively. Not to mention the conversation around the data mesh architecture that has further popularized this concept. Speaking of the data mesh, I’ve seen two kinds of people in the data community: those who believe it is an upcoming trend, and those who argue that we have been practicing data mesh all along.
Regardless of which group you belong to, we can all agree that data should be managed as a product. Aligning with this belief, we at DataHub have taken a community-guided approach to defining, developing, and building the Data Product within DataHub.
In this article, I share an overview of DataHub’s vision and current model for Data Products, as well as our vision and commitments for the future.
What is a Data Product?
To put it simply, Data Products in DataHub are simply an extension of:
- treating “data as a product” and
- applying product thinking to data assets.
Data Products represent collections of assets that are important to you – that you can combine to manage and maintain. Data Products have owners, tags, glossary terms, and documentation.
Data Products are a way to organize and manage your Data Assets, such as Tables, Topics, Views, Pipelines, Charts, Dashboards, etc., within DataHub. They belong to a specific Domain and can be easily accessed by various teams or stakeholders within your organization.
Data Products: Why We Need to Look at Data as a Product
Here are three reasons that have guided our thinking about Data Products and why the community needs them:
- Equipping business users: They enable a move towards discoverable and documented data assets that equip non-technical users to use them – without having to rely on analysts or developers.
- Interconnectivity and collaboration: A key function of Data Products is to enhance the sharing capabilities between teams and foster collaboration across different data products. By defining a Data Product, or marking specific components within it as internal or shareable, downstream teams can depend on the outputs of other data products.
This interconnectedness allows for synergistic relationships and empowers organizations to leverage existing data assets effectively. - Integration with existing workflows: To bridge the gap between business users and developers, we need to incorporate familiar development practices into data product definitions. This approach ensures that changes made to data product definitions are seamlessly incorporated, thereby streamlining workflows and facilitating collaboration.
At DataHub, bringing business users and technical users together by enabling Shift-Left practices in metadata – for instance, by enabling data products to be
- defined using YAML and
- managed as code.
(More on this in the next section)
Data Products: Inputs from the DataHub Community
We wanted the community to guide our understanding and practical implementation of Data Products. We set up a dedicated Data Products channel, Design Data Product Entity, to bring the community together to guide us on
- What Data Products look like to them
- How Data Products should be represented within DataHub
The community delivered, and how – with ideas, visualizations, use cases, academic papers, and more.






Recognizing the complexity of data products, we adopted a minimum viable product (MVP) strategy for modeling. Here’s how this played out:
- What: Our focus was to define boundaries around relevant data elements, such as pipelines, tables, and dashboards, to create distinct data products.
- Why: This approach enables attaching ownership tags, glossary terms, and comprehensive documentation to each data product. Of course, further iterations will be necessary to refine and expand the data product entity.
- How: Here’s a simple raw technical metadata graph we’re all familiar with – with streams, tables, processing pipelines, more tables, and dashboards.

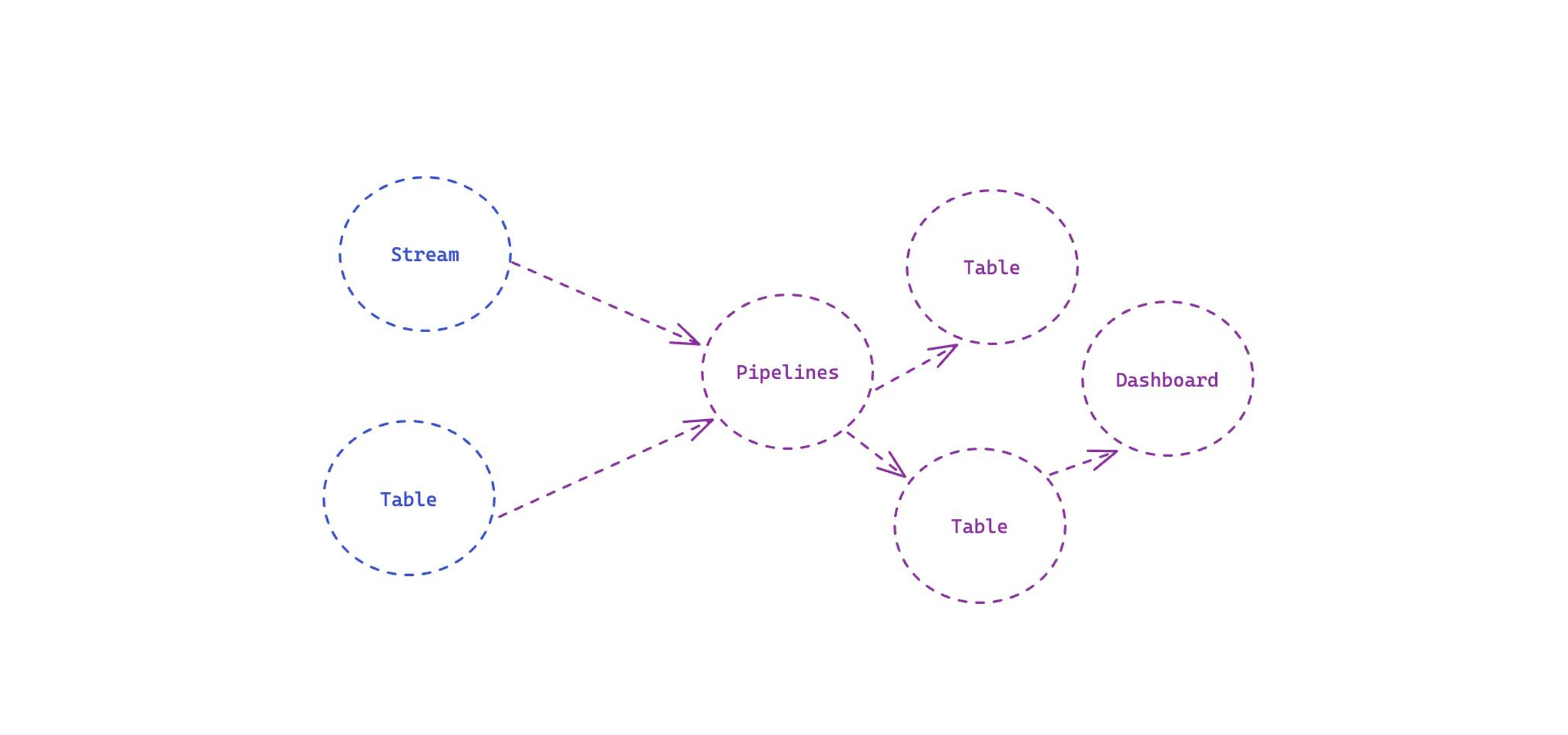
Data Products within DataHub help you “define a boundary around these assets to create and define your own Data Product”
For example, here’s a Revenue Data Product, with the pipelines that your team works on, the tables they produce, and this is the dashboard that's getting exported.


And with that, you have your own Data Product with ownership tags, glossary terms, and documentation – that you manage and can share with other teams.
In the next iteration, we’re working on capabilities that help you to mark certain elements within the Data Product (say, as being internal or shareable, as in the example below).


This way, downstream teams can depend on outputs from your Data Product in the definition of their Data Product.
The DataHub Approach to Modeling Data Products
With Data Products, we were clear about one thing: managing Data Product definitions just like we manage everything else – like code.
As I mentioned earlier, this meant enabling business users (usually personas that are not familiar with git) and technical users (who are very familiar with git-based practices) to participate in Shift-left approaches to manage into the Data Product definition life cycles.
With DataHub’s approach to Data Products, you can bring the business user and the developer
together through the ability to
- define data products as YAML,
- check them into Git (and have them synced with DataHub)
- enable the business user can collaborate and refine the definition of the data product
- flow changes back right where they started so that we no longer have to have these two worlds live so far from each other.


Creating a Data Product in DataHub
You can create a Data Product in DataHub using the UI or via a YAML file.


DataHub also comes with a YAML-based Data Product spec for defining and managing Data Products as code. Here is an example of a Data Product named "Pet of the Week" which belongs to the Marketing domain and contains three data assets. The Spec tab describes the JSON Schema spec for a DataHub data product file.


Assigning Assets to a Data Product
You can assign an asset to a Data Product using the Data Product page or the Asset's page as shown below.

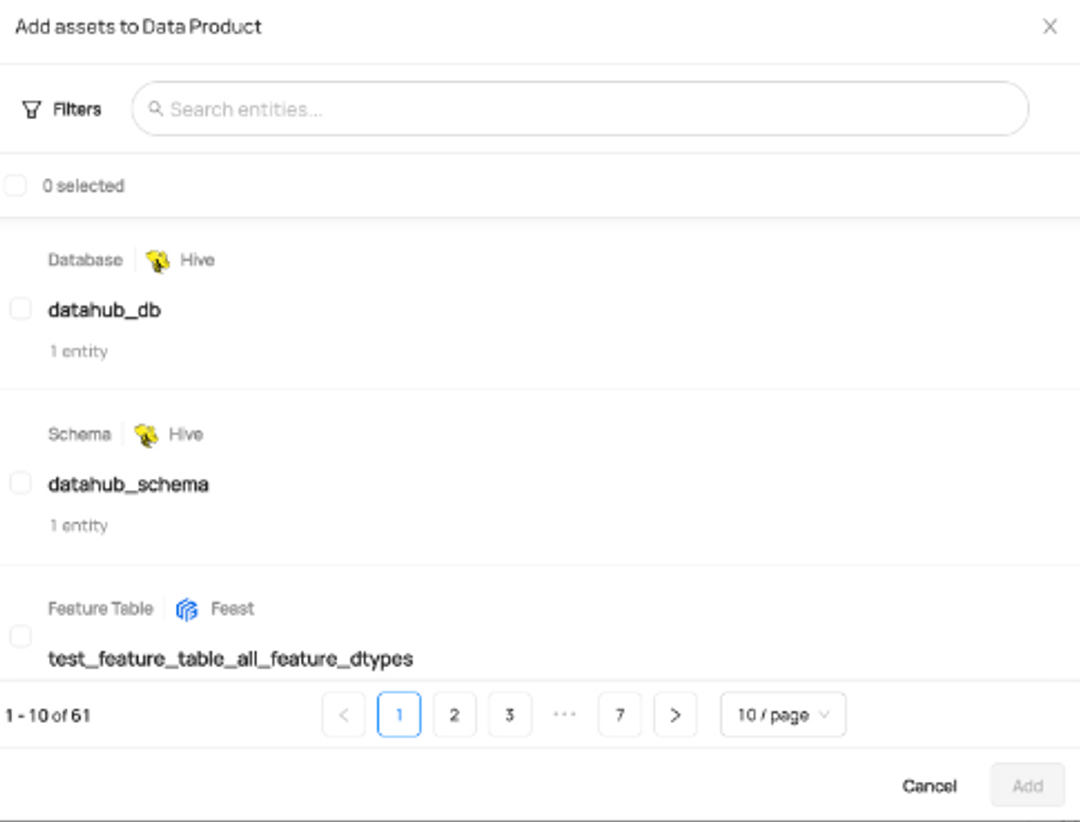

(Ways to add Data Assets to a Data Product in DataHub)
Here’s a DataHub Townhall video recorded in May 2023, showing you exactly how Data Products in DataHub work.
Link: https://www.youtube.com/watch?v=vpz62mpvUVs
The best part is you can also create views in DataHub that only include Data Products – for when you want your users to stay firmly in the Data Product space – without having to view tables, dashboards, and other more technical aspects.
The Way Ahead for Data Products
We believe that Data Products can revolutionize the way enterprises manage, share, and they are fundamental to effective data management, and it’s only by embracing the concept of data as a product that organizations can unlock the full potential of their data assets.
As we move forward, we are committed to keeping the community involved in shaping the future of Data Products. We’d love to hear from you. Take Data Products out for a spin and let us know what you think.
Our Data Products Feature Page has everything you need to get started.
Connect with Acryl and DataHub

NEXT UP

Governing the Kafka Firehose
Kafka’s schema registry and data portal are great, but without a way to actually enforce schema standards across all your upstream apps and services, data breakages are still going to happen. Just as important, without insight into who or what depends on this data, you can’t contain the damage. And, as data teams know, Kafka data breakages almost always cascade far and wide downstream—wrecking not just data pipelines, and not just business-critical products and services, but also any reports, dashboards, or operational analytics that depend on upstream Kafka data.

When Data Quality Fires Break Out, You're Always First to Know with Acryl Observe
Acryl Observe is a complete observability solution offered by Acryl Cloud. It helps you detect data quality issues as soon as they happen so you can address them proactively, rather than waiting for them to impact your business’ operations and services. And it integrates seamlessly with all data warehouses—including Snowflake, BigQuery, Redshift, and Databricks. But Acryl Observe is more than just detection. When data breakages do inevitably occur, it gives you everything you need to assess impact, debug, and resolve them fast; notifying all the right people with real-time status updates along the way.


John Joyce
2024-04-23

Five Signs You Need a Unified Data Observability Solution
A data observability tool is like loss-prevention for your data ecosystem, equipping you with the tools you need to proactively identify and extinguish data quality fires before they can erupt into towering infernos. Damage control is key, because upstream failures almost always have cascading downstream effects—breaking KPIs, reports, and dashboards, along with the business products and services these support and enable. When data quality fires become routine, trust is eroded. Stakeholders no longer trust their reports, dashboards, and analytics, jeopardizing the data-driven culture you’ve worked so hard to nurture
John Joyce
2024-04-17