
DataHub 2022 in Review
Open Source
Metadata Management
Metadata
Community
Data Engineering


Open Source
Metadata Management
Metadata
Community
Data Engineering
Happy 2023, Data Hub Community!
I hope this finds you happy, well-rested and refreshed for the new year ahead.
2022 was a tremendous year of growth and activity for DataHub. Our Slack Community nearly tripled to 5.7k members (across 57 countries & 27 local timezones!), and we merged 2,300+ PRs from over 200 contributors into the open-source project — more than double the volume from the year prior.
So, who are all these wonderful people, and what amazing things did we build? Let’s take a few minutes to reflect on all that has happened in the past 12 months!
Who We Are
I surveyed the DataHub Community in December 2022 to better understand the types of roles & industries that are common and where folks are in their DataHub adoption journey.
The three most common roles in the Community are Data Engineer (38%), Software Engineer (18%), and System Architect (12%). I’m excited to see more & more Data Analysts & Product Managers join the Community; it’s invigorating to see DataHub end-users joining the conversation!


In the DataHub adoption journey, nearly 2/3 of respondents reported deploying to production or rolling out the tool to their stakeholders vs. 27% in December 2021. This is an exciting shift and is an excellent indicator of the maturity of the OSS project & progress made by our Community Members.
The Tools We Use
We wanted to understand better the tools that are most commonly used in our Community Members’ data stacks, and boy, are there many data tools in the mix!
Percentage of survey respondents that reported using each tool within their data stack.

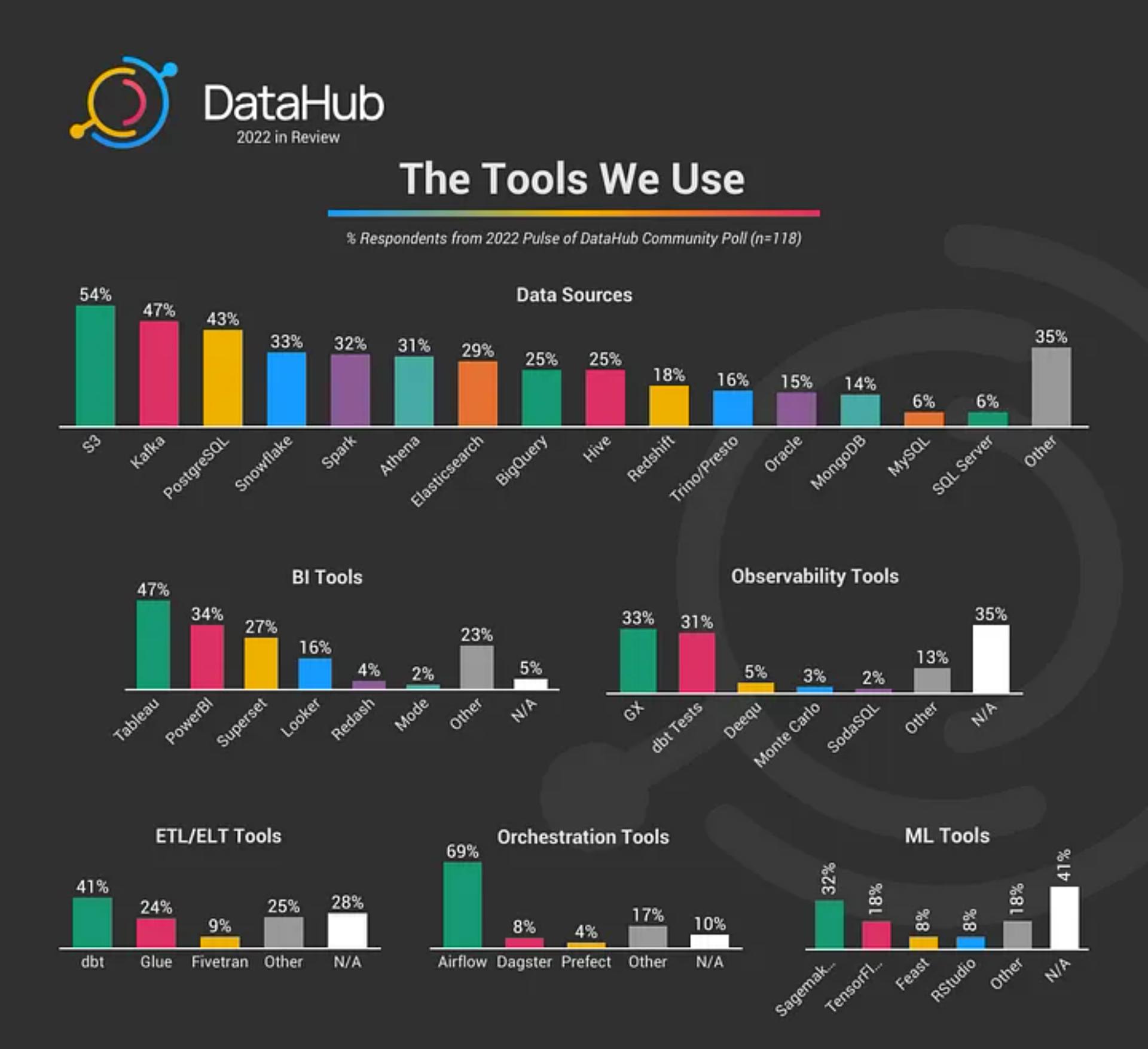
Percentage of survey respondents that reported using each tool within their data stack.
This is incredibly helpful in informing where we should prioritize integration support between DataHub & external tools and identify potential cross-community partnerships.
How We Interacted in 2022
DataHub Slack was buzzing day in and day out. We consistently saw between 700–1,000 weekly active users making for a vibrant conversation around metadata management use cases, data governance best practices, DataHub troubleshooting, and more.

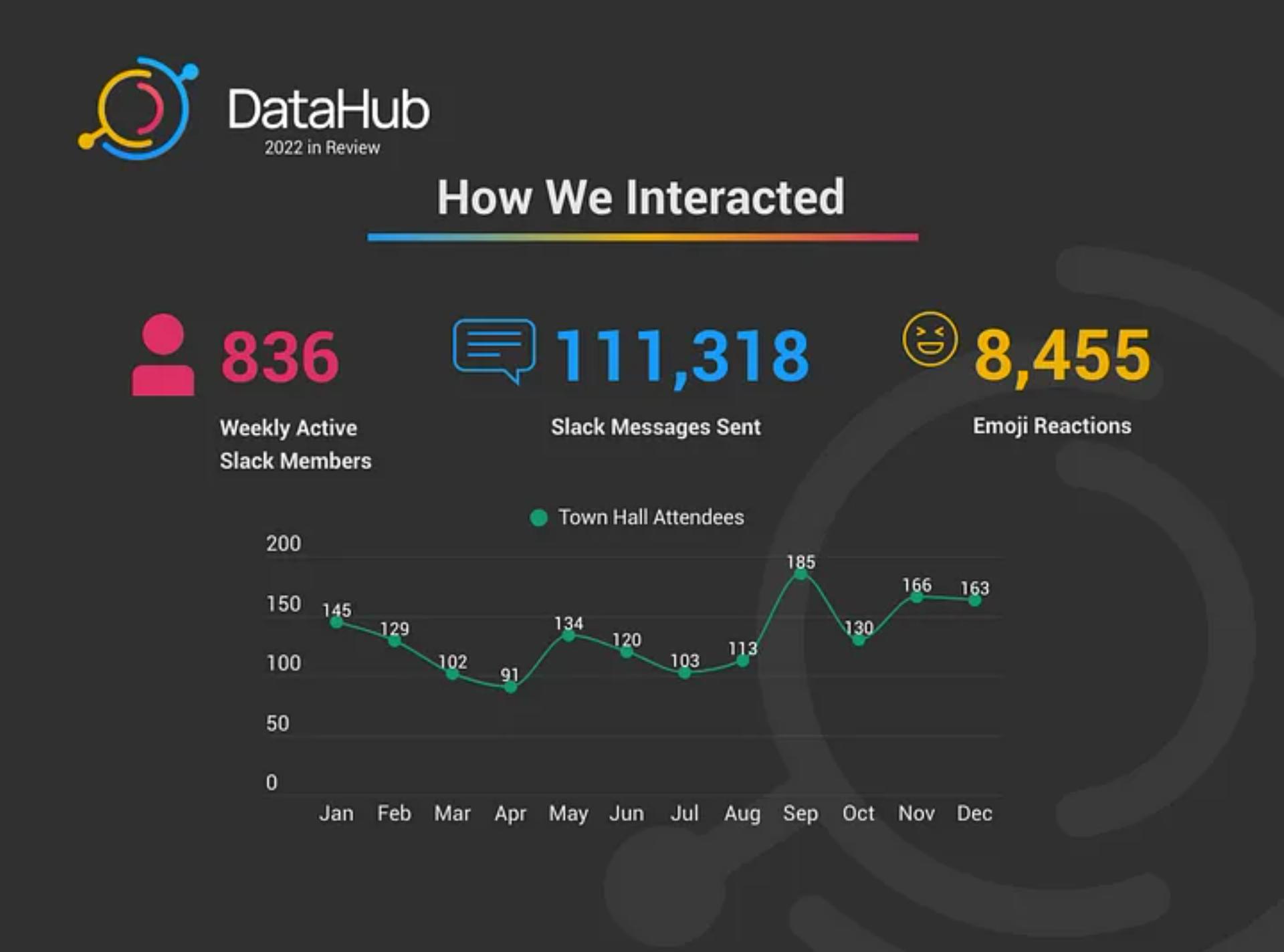
Our Town Halls were always the highlight of my month — it’s a fantastic opportunity to connect with Community Members live & to share feature highlights, DataHub adoption stories, and previews of what’s to come.
Join us at our next Town Hall! RSVP here.
How We Contributed in 2022
As mentioned earlier, we merged in 2x as many PRs from 2x as many contributors in 2022 compared to the prior year. It’s incredible to see 200+ community members collectively joining together to build this project!

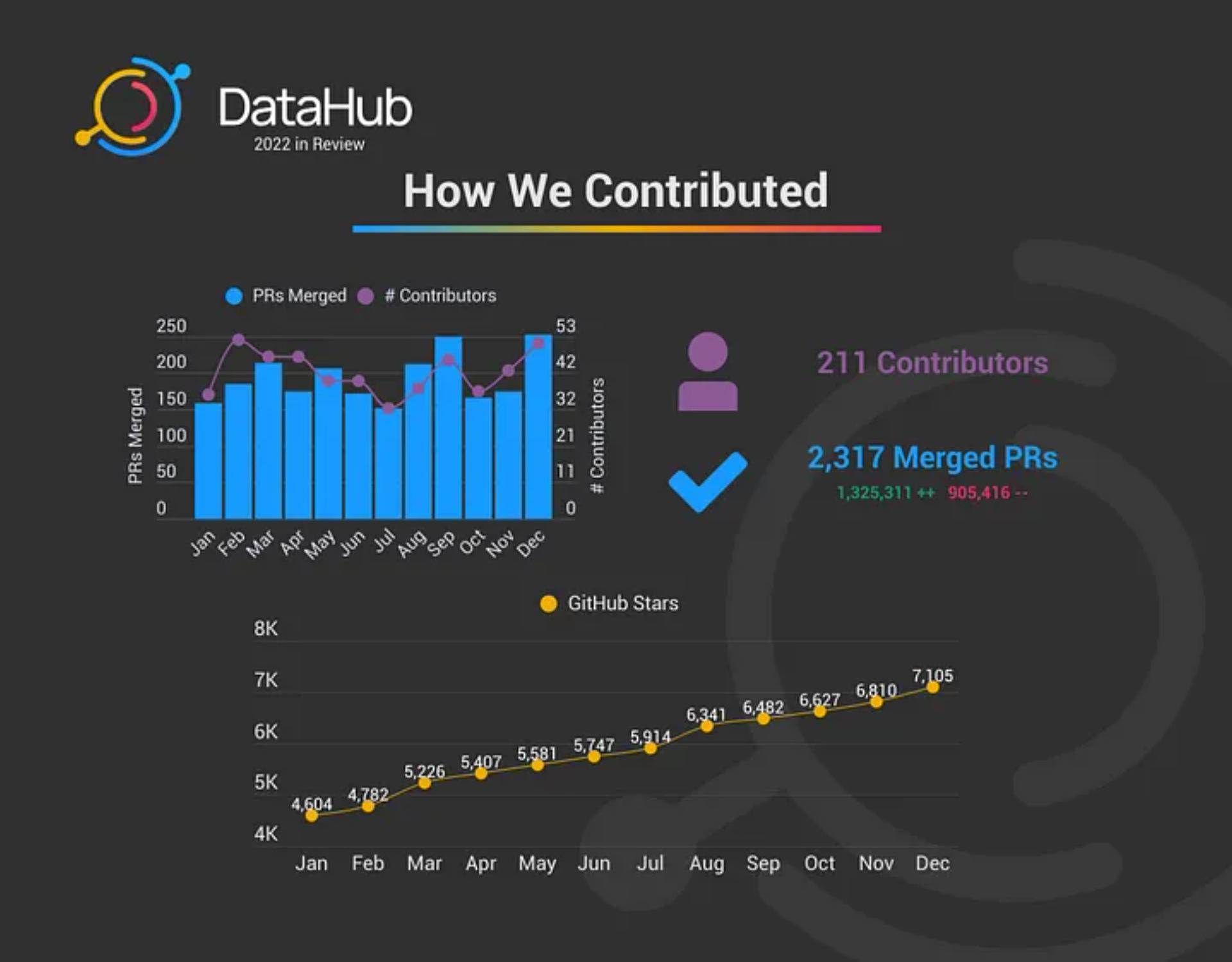
What We Built in 2022
2022 was a feature-rich year for the DataHub project. We took significant steps towards making the UI more user-friendly for business stakeholders, providing more flexibility for developers to interact with DataHub’s APIs, and building robust integration support for widely adopted data tools.
Here are some highlights of what we shipped in 2022 —


I am endlessly grateful to work alongside such talented and committed folks in our Community. It’s been the honor of my career to contribute toward this space for Data Practitioners to come together and tackle big, hairy problems.


:teamwork:
I’m so excited to team up with you all to build amazing things in 2023. We’ll be sharing more details on our near-term roadmap soon — stay tuned!
See y’all in Slack 😊
Connect with DataHub
Join us on Slack • Sign up for our Newsletter • Follow us on Twitter
Open Source
Metadata Management
Metadata
Community
Data Engineering

NEXT UP

Governing the Kafka Firehose
Kafka’s schema registry and data portal are great, but without a way to actually enforce schema standards across all your upstream apps and services, data breakages are still going to happen. Just as important, without insight into who or what depends on this data, you can’t contain the damage. And, as data teams know, Kafka data breakages almost always cascade far and wide downstream—wrecking not just data pipelines, and not just business-critical products and services, but also any reports, dashboards, or operational analytics that depend on upstream Kafka data.

When Data Quality Fires Break Out, You're Always First to Know with Acryl Observe
Acryl Observe is a complete observability solution offered by Acryl Cloud. It helps you detect data quality issues as soon as they happen so you can address them proactively, rather than waiting for them to impact your business’ operations and services. And it integrates seamlessly with all data warehouses—including Snowflake, BigQuery, Redshift, and Databricks. But Acryl Observe is more than just detection. When data breakages do inevitably occur, it gives you everything you need to assess impact, debug, and resolve them fast; notifying all the right people with real-time status updates along the way.


John Joyce
2024-04-23

Five Signs You Need a Unified Data Observability Solution
A data observability tool is like loss-prevention for your data ecosystem, equipping you with the tools you need to proactively identify and extinguish data quality fires before they can erupt into towering infernos. Damage control is key, because upstream failures almost always have cascading downstream effects—breaking KPIs, reports, and dashboards, along with the business products and services these support and enable. When data quality fires become routine, trust is eroded. Stakeholders no longer trust their reports, dashboards, and analytics, jeopardizing the data-driven culture you’ve worked so hard to nurture
John Joyce
2024-04-17