
PII Classification just got easier with DataHub
Data Governance
Metadata
Compliance
Data Engineering
Snowflake


Data Governance
Metadata
Compliance
Data Engineering
Snowflake
Managing sensitive data lies at the core of modern data governance. Whether you’re navigating the intricacies of GDPR & CCPA or on the hook for responsibly granting data access to others, it’s critical to have a strategy around tagging sensitive data.


Photo by Philipp Katzenberger on Unsplash
DataHub’s popular Business Glossary is a powerful way to model PII and compliance types and classify data entities across your data stack. In addition to manually assigning these classifications, DataHub can now automatically classify and tag sensitive data or PII — right at ingestion — making data discovery and access seamless, scalable, and secure.
What PII classification in DataHub looks like
DataHub’s automated PII classification identifies sensitive columns and the tables containing them during ingestion, so these columns are automatically associated with predefined PII-related glossary terms.

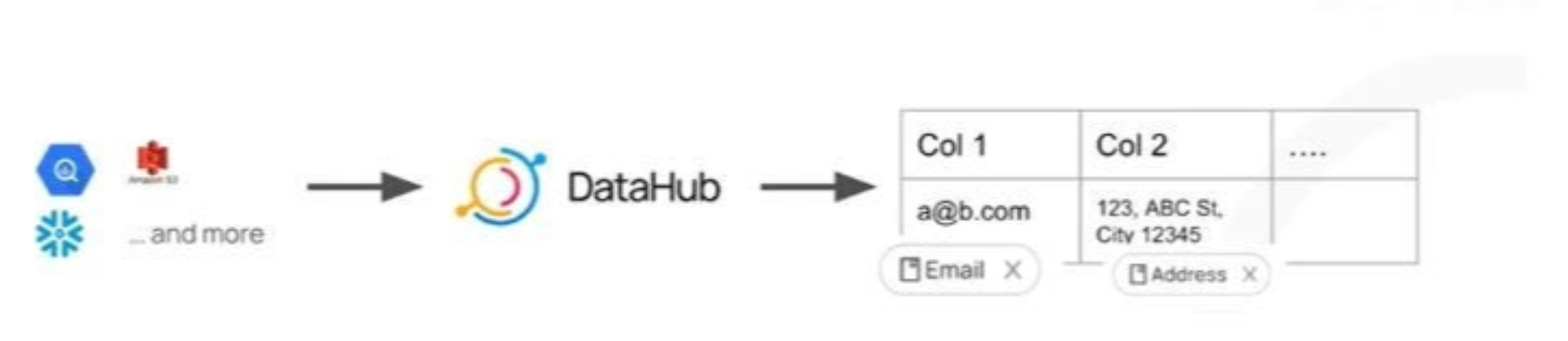
Currently, DataHub’s automated PII detection works to detect info types including full name, gender, full name, email phone, street address, credit card number, SSN (Social Security Number), driver’s license numbers, IBAN (international bank account number), bank SWIFT codes, and IP addresses.
TLDR: How DataHub’s automated PII classification works
The TLDR version
Simply put, this opt-in functionality analyzes your metadata at a column level to tag a PII-related glossary term (info type) for every column.
At ingestion, the DataHub PII detection module analyzes each column for the presence of an info type, by
- checks for the presence of certain factors (referred to as Prediction Factors)
- assigns a configurable weighting to each Prediction Factor,
- computes an overall confidence level/score for an info type’s presence,
and - proposes the relevant info type as a glossary term for that column — if the score exceeds the confidence level threshold set by you.
As a DataHub admin, you have complete control over
- enabling the PII classification functionality
- deciding the info types to be processed, and
- setting the confidence-level threshold for the auto-classification of info types
Check out DataHub’s PII Classification in action in this video:
A detailed look at DataHub’s PII classification workflow
DataHub’s classifier implementation uses a standalone library to predict PII info types. It uses the following factors (referred to as Prediction Factors) to propose the info type applicable to each column
- Name
- Description
- Datatype
- Values
The presence of each Prediction Factor is detected using simple rule-based matching and libraries like Spacy (or other common ML libraries), and a confidence score is assigned for the presence of each Prediction Factor.
The module then uses a customizable weighted combination of these different confidence scores to compute an overall level that determines if the proposed info type applies to the column. You can configure the weightage of each Prediction Factor to control how it impacts the final value.
The resulting score is compared against a configurable threshold (default configuration uses a threshold of 0.7) to determine if the info term should be applied to the column.
Configuring classification info types
As a DataHub admin, you can customize your YAML recipe to configure how each info type is automatically classified during ingestion
All you need to do is configure the following parameters as they apply to your use case:
- Prediction Factor weightage — the weight of each prediction factor to be used in the final computation of the info type classification score
- Name — the regex list to be matched against the column name
- Description — the regex list to be matched against the column description
- Datatype- the datatypes to be matched against column datatype
- Prediction Type — regex or library
- regex — regex list to be matched against column values
- library — library name to be used to evaluate column values
Here’s an example:


Using DataHub’s PII Classification Module
To use the classification, all you need to do is add the classification section to the recipe and enable it.

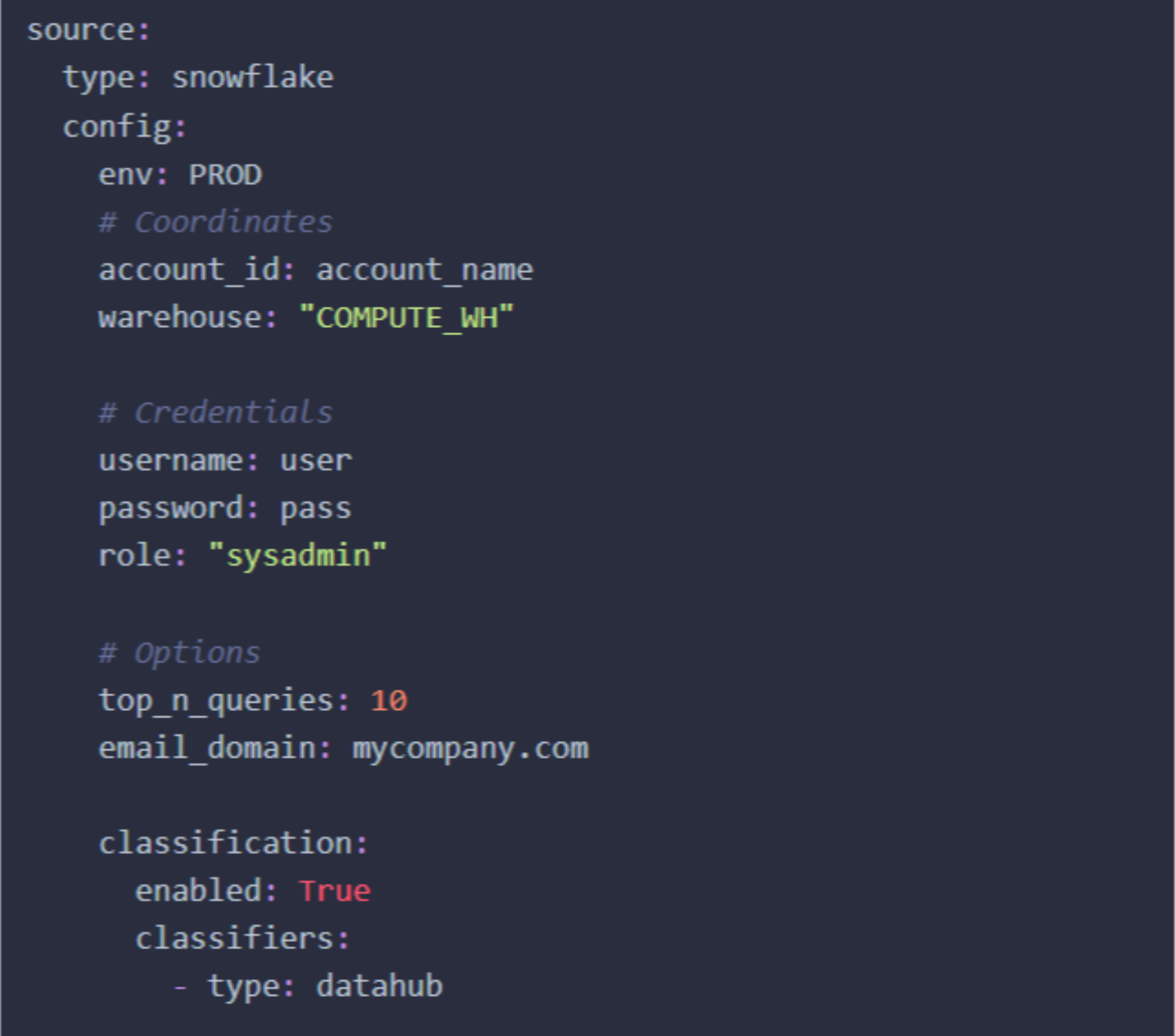
Here’s an example of how you can customize and configure your recipe for auto-classifying the ‘Email’ info type based on the criteria and confidence threshold you set.

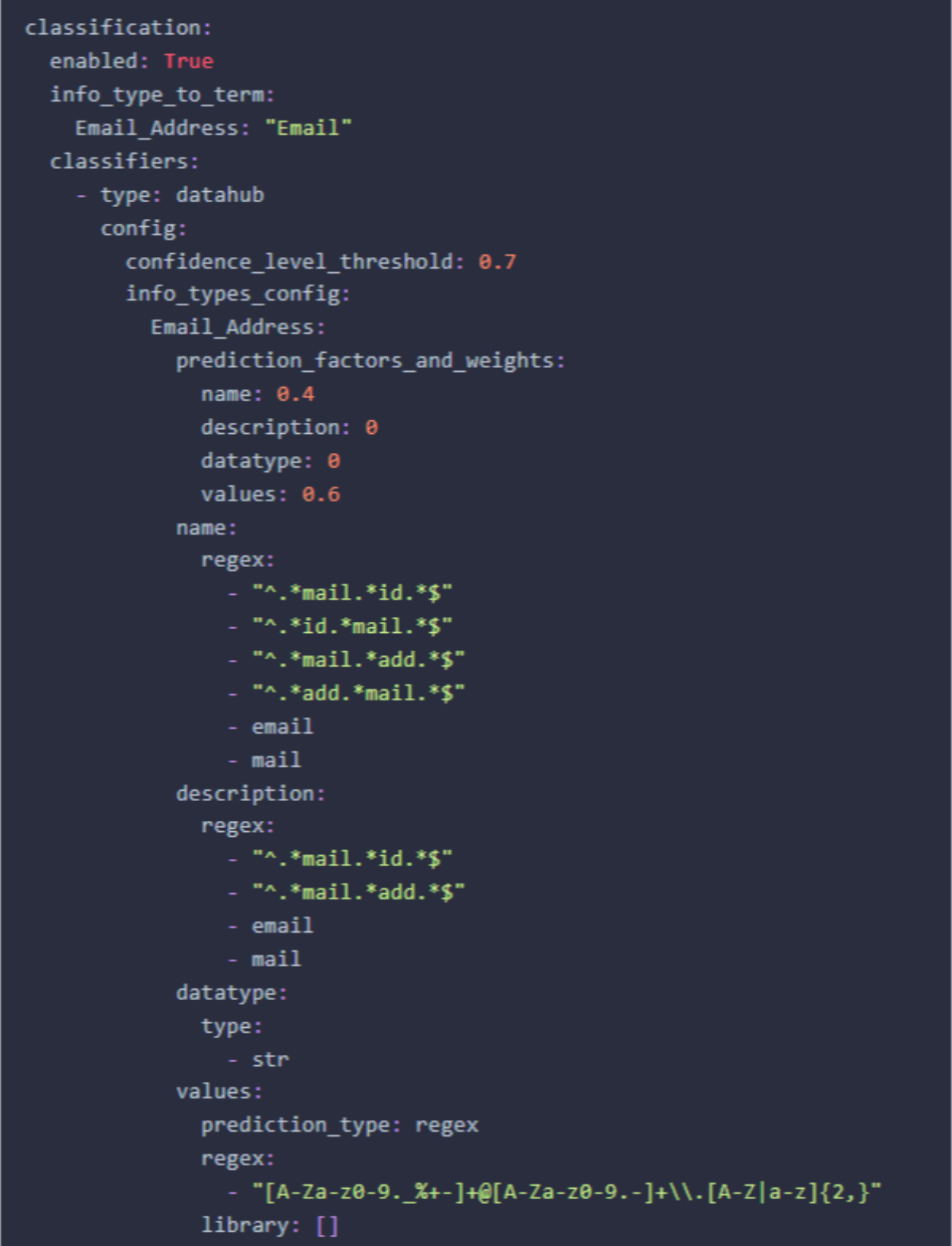
To understand how you can use more advanced configurations for your info types, check out our Classification Feature Guide.
What’s next?
DataHub’s PII classification feature is currently available for Snowflake; we are excited to extend it to other SQL-based sources and are eager for feedback from the Community about how we can improve the integration experience.
We’re looking for contributors — join the DataHub Community to make this happen!
Connect with DataHub
Join us on Slack • Sign up for our Newsletter • Follow us on Twitter
Data Governance
Metadata
Compliance
Data Engineering
Snowflake

NEXT UP

Governing the Kafka Firehose
Kafka’s schema registry and data portal are great, but without a way to actually enforce schema standards across all your upstream apps and services, data breakages are still going to happen. Just as important, without insight into who or what depends on this data, you can’t contain the damage. And, as data teams know, Kafka data breakages almost always cascade far and wide downstream—wrecking not just data pipelines, and not just business-critical products and services, but also any reports, dashboards, or operational analytics that depend on upstream Kafka data.

When Data Quality Fires Break Out, You're Always First to Know with Acryl Observe
Acryl Observe is a complete observability solution offered by Acryl Cloud. It helps you detect data quality issues as soon as they happen so you can address them proactively, rather than waiting for them to impact your business’ operations and services. And it integrates seamlessly with all data warehouses—including Snowflake, BigQuery, Redshift, and Databricks. But Acryl Observe is more than just detection. When data breakages do inevitably occur, it gives you everything you need to assess impact, debug, and resolve them fast; notifying all the right people with real-time status updates along the way.


John Joyce
2024-04-23

Five Signs You Need a Unified Data Observability Solution
A data observability tool is like loss-prevention for your data ecosystem, equipping you with the tools you need to proactively identify and extinguish data quality fires before they can erupt into towering infernos. Damage control is key, because upstream failures almost always have cascading downstream effects—breaking KPIs, reports, and dashboards, along with the business products and services these support and enable. When data quality fires become routine, trust is eroded. Stakeholders no longer trust their reports, dashboards, and analytics, jeopardizing the data-driven culture you’ve worked so hard to nurture
John Joyce
2024-04-17