
Tech Deep Dive: DataHub Metadata Service Authentication
DataHub
Metadata
Open Source
Modern Data Stack
Tech Deep Dive


DataHub
Metadata
Open Source
Modern Data Stack
Tech Deep Dive
DataHub has recently introduced authentication in the Metadata Service, the service responsible for storing & serving the Metadata Graph. In this article, we provide a technical deep dive into the new capabilities, including why they were built, how they were built, how to use them, and where we’re going next.
The Motivations
Two Java services sit at the center of DataHub’s architecture:
- DataHub Frontend Proxy (datahub-frontend) — Resource server that routes requests to downstream Metadata Service
- DataHub Metadata Service (datahub-gms) — Source of truth for storing and serving DataHub Metadata Graph
Up until now, the Frontend Proxy was responsible for all authentication. When a user navigated to the DataHub UI in their browser, the proxy would perform the following steps:
- Check for the presence of a special
PLAY_SESSIONcookie - Attempt to validate the
PLAY_SESSIONcookie - If the cookie was invalid, the user would be redirected to the DataHub native login screen (for JAAS authentication) or to a third-party OIDC Identity Provider to perform SSO authentication
- If the cookie was valid, the user would be redirected to the DataHub home page


The Old World: Frontend Proxy handles all authentication
Upon successful authentication, a stateless session cookie would be set in the user’s browser and all subsequent requests would be authenticated using this session cookie.
If a request had been authenticated by the Frontend Proxy, it was trusted by the Metadata Service. There was no native authentication inside of the Metadata Service.
Problems with this approach
The major problem with this approach is that there was no formal support for making authenticated requests to the APIs exposed by the Metadata Service, including to the GraphQL API and the Rest.li Ingestion APIs. This meant that anyone with network access to the DataHub services could successfully make unauthenticated requests.
As a result, many companies using DataHub in production were inclined to build workarounds, for example:
- Setting up a custom authentication proxy in front of the Metadata Service
- Routing requests through the Frontend Proxy, using a session cookie manually extracted from a user’s browser session for authentication
In addition to these challenges, we were getting feedback from the DataHub Community that many companies would benefit from both Rest & Kafka-based metadata ingestion sharing a common authentication mechanism.
Introducing DataHub Metadata Service Authentication
To address these problems, we decided to build authentication into the Metadata Service itself, meaning requests would not be considered trustworthy until verified by the Metadata Service.
Requirements
In designing the new subsystem, there were a few core requirements we wanted to include.
First and foremost, we wanted extensibility & configurability, recognizing that a high degree of flexibility would be required to accommodate the wide-ranging needs of the DataHub Community. Specifically, extensibility meant that it should be straightforward to plug in new mechanisms to authenticate inbound requests, while configurability meant that it should be possible to customize and toggle particular authentication mechanisms by exposing accessible configuration knobs.
Additionally, we wanted to provide a batteries-included way to generate and verify time-bound credentials for use with DataHub APIs, i.e. API keys, built on top of the new authentication subsystem. This will in practice enable DataHub operators to make authenticated requests to DataHub APIs for metadata ingestion pipelines and ad-hoc programmatic use cases.
New Concepts & Key Components
To accommodate these requirements, we had to model a few new abstractions inside the DataHub Metadata Service:
- Actor: A unique identity or principal accessing DataHub
- Authenticator: A pluggable component for authenticating an Actor from an inbound request
- Authenticator Chain: A group of Authenticators executed in sequence
- DataHub Access Token: Credentials granting access to DataHub APIs
- DataHub Token Service: A component responsible for generating & verifying Access Tokens
In the following sections, we’ll take a closer look at each individually.
What is an Actor?
An Actor is a concept representing a unique identity or principal performing actions on DataHub.
An actor can be characterized by 2 attributes:
- Type — The type of actor making a request. The purpose is to in the future distinguish between a “user” & “service” actor. Currently, the “user” actor type is the only one formally supported.
- Id — A unique identifier for the actor within DataHub. This identifier is in turn used when converting from the “Actor” concept into a Metadata Entity “urn” (e.g. urn:li:corpuser:<id> ).
What is an Authenticator?
An Authenticator is a pluggable component inside the Metadata Service that is responsible for authenticating an inbound request, provided context about the request. The act of Authentication means associating a unique Actor with a request.
There can be many different implementations of Authenticator. For example, there can be implementations that
- Verify the authenticity of an access token granted by a 3rd party (or DataHub itself)
- Check a username/password combination against a remote database (ie. LDAP / Basic Authentication)
A key goal of this abstraction is extensibility: a custom Authenticator can be developed to authenticate requests based on an organization’s unique needs.
DataHub will ship with two configurable Authenticator implementations by default:
- DataHubSystemAuthenticator: Verifies that inbound requests have originated from inside DataHub itself using a shared system identifier and secret. This authenticator is always present.
- DataHubTokenAuthenticator: Verifies that inbound requests contain a DataHub-issued Access Token (discussed in detail) in their ‘Authorization’ header. This authenticator is required if Metadata Service Authentication is enabled.
What is an Authenticator Chain?
An Authenticator Chain is a series of Authenticators that are configured to execute in series, with the goal of associating an Actor with an inbound request.
The chain allows operators of DataHub to configure multiple ways to authenticate a given request, for example via LDAP or via 3rd party access token.
The Authenticator Chain can be configured in the Metadata Service application.yml file under authentication.authenticators:
authentication:
# Configure Authenticator Chain
authenticators:
- type: com.datahub.authentication.Authenticator1
configs:
# Authenticator-specific configuration values
config1: value1
...
- type: com.datahub.authentication.Authenticator2
....What is a DataHub Token Service? What are Access Tokens?
As part of the new authentication subsystem comes an important new component called the DataHub Token Service. The purpose of this component is twofold:
- Generate Access Tokens that grant access to Metadata Service APIs
- Verify the validity of Access Tokens presented to Metadata Service APIs
Access Tokens granted by the Token Service take the form of JSON Web Tokens, a type of stateless token which has a finite lifespan & is verified using a unique signature.
JWTs contain a set of claims embedded within them, used to verify the issuer and identify the bearer’s identity. Tokens issued by the DataHub Token Service contain the following claims:
- exp: the expiration time of the token
- version: version of the DataHub Access Token for purposes of evolvability (currently 1)
- type: The type of token, currently SESSION (used for UI-based sessions) or PERSONAL (used for personal access tokens)
- actorType: The type of Actor associated with the token. Currently, USER is the only type supported.
- actorId: The id of the Actor associated with the token.
Access Tokens can be granted by the token service in two scenarios:
- UI Login: When a user logs into the DataHub UI, for example via JaaS or OIDC, the
datahub-frontendservice issues a request to the Metadata Service to generate a SESSION token on behalf of the user logging in. - Generating Personal Access Tokens: When a user requests to generate a Personal Access Token, which will be described below.
Now that we’re familiar with the concepts being introduced, let’s take a look at the new capabilities that have been built on top of the Authentication system.
Putting it all together
The following diagram illustrates the new authentication system at a glance.

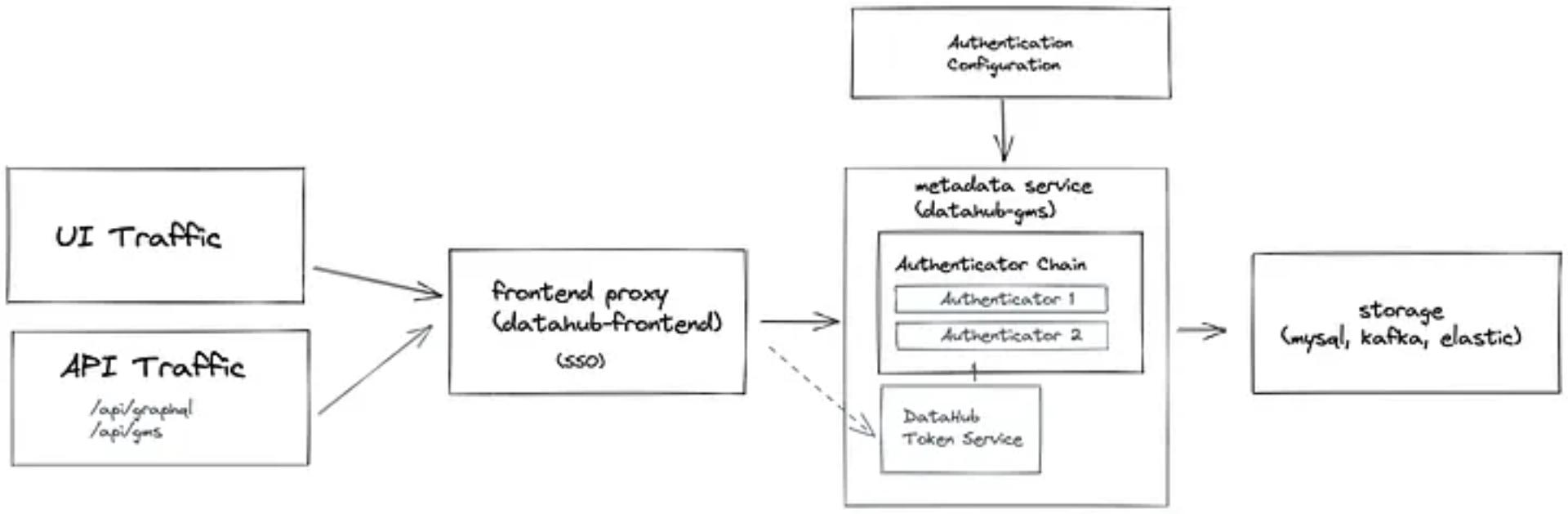
The New World: Metadata Service handles authentication
The most notable change is that most responsibility for Authentication has been shifted to the Metadata Service.
To perform authentication, the Metadata Service will be configured to invoke an Authenticator Chain on every inbound request, which will be ultimately responsible for allowing or denying the request.
The Authenticator Chain in turn consists of a set of Authenticators executed in series, each with the goal of verifying the trustworthiness of the inbound request. If no Authenticator in the chain succeeds to authenticate a request, the request will be rejected. If Authentication succeeds in at least one Authenticator, it will be allowed to proceed.
A set of special components will come with DataHub out of the box: the DataHub Token Service and DataHub Token Authenticator. The Token Service will be responsible for generating and validating DataHub Access Tokens, while the DataHub Token Authenticator will use the Token Service to attempt to validate Bearer Tokens provided in the Authorizationheader of inbound requests.
Finally, DataHub Frontend Proxy will remain responsible for UI-initiated login / SSO. Successful completion of the login step when navigating to the UI will result in the issuance of a Metadata Service Access Token via a request to the DataHub Token Service. This Access Token will be embedded in a normal session cookie and forwarded to the Metadata Service on each UI-initiated request.
New Capabilities
Personal Access Tokens
As part of Metadata Service Authentication, we’ve provided a way to easily generate an Access Token for programmatic use with DataHub APIs. We call this feature Personal Access Tokens.
Personal Access Tokens have a finite lifespan and inherit the privileges granted to the user who generates them (e.g. by DataHub Policies). They can be generated by navigating to the ‘Settings’ Tab of the DataHub UI.


And clicking Generate Personal Access Token.


Using a Personal Access Token
Once a token is generated, it can be used to make authenticated requests to DataHub’s GraphQL and/or Rest.li Ingestion APIs via either DataHub Frontend Proxy or the Metadata Service directly. It can also be used to authenticate traffic during Metadata Ingestion via Recipe.

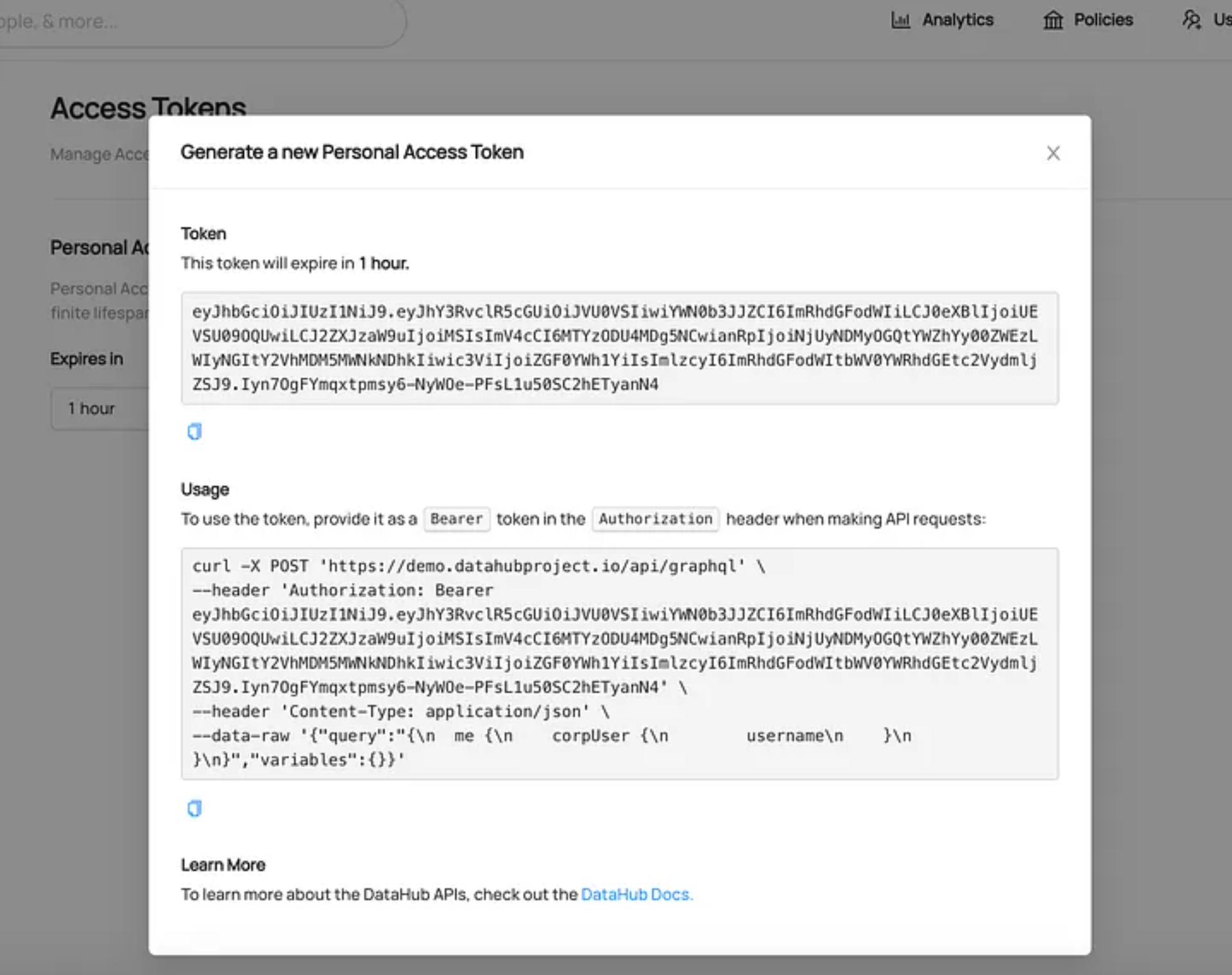
Copy the generated Access Token to authenticate your request to DataHub APIs
When making programmatic requests to DataHub APIs, a generated token should be included as a Bearer token in the Authorization header:
Authorization: Bearer <generated-access-token>For example, using a curl to fetch the “datahub” user via the DataHub Frontend Proxy service:
curl 'http://localhost:9002/api/gms/entities/urn:li:corpuser:datahub' -H 'Authorization: Bearer <access-token>Without an access token, making programmatic requests will result in a 401 result from the server if Metadata Service Authentication is enabled.
Metadata Ingestion Authentication
Once you’ve generated a Personal Access Token, it can be used to authenticate traffic from the Metadata Ingestion Framework by embedding it in ingestion Recipes.
Simply provide the generated token in the token field of the sink configuration block:
source:
# source configs
sink:
type: "datahub-rest"
config:
...
token: <generated-personal-access-token>Enabling Metadata Service Authentication
On first release, Metadata Service Authentication will be opt-in. This means that operators may continue to use DataHub without Metadata Service Authentication without interruption.
To enable Metadata Service Authentication in your DataHub deployment, simply set the METADATA_SERVICE_AUTH_ENABLED environment variable to "true" for the datahub-gms AND datahub-frontend containers.
After setting the configuration flag, simply restart the Metadata Service to start enforcing Authentication.
The Future of DataHub Authentication
The changes detailed in this article are scheduled for release in version 0.8.18 of DataHub. They represent the beginning of a new authentication subsystem that will serve as a foundation that will continue to evolve in response to the needs of the DataHub Community.
In fact, we’ve already begun to receive requests for additional features, including:
- Dynamic Authenticator Plugins: Configure + register custom Authenticator implementations, without forking DataHub.
- Service Accounts: Create service accounts and generate Access tokens on their behalf.
- Kafka Ingestion Authentication: Authenticate ingestion requests coming from the Kafka ingestion sink inside the Metadata Service.
- Access Token Management: Ability to view, manage, and revoke access tokens that have been generated. (Currently, access tokens include no server-side state, and thus cannot be revoked once granted)
We plan to prioritize these based on input from the wider DataHub Community. Missing something important? Don’t hesitate to submit an additional DataHub Feature Request for review.
Concluding Thoughts
The introduction of the new Authentication subsystem represents a major upgrade to DataHub with respect to security, extensibility, & usability. Operators of DataHub can now have peace of mind, knowing that all traffic to DataHub APIs can be trusted.
This lift would not have been possible without the rich collaboration occurring within the vibrant DataHub open source community. Special thanks to Alasdair McBride, Wan Chun Chen, & Gabe Lyons for the input & review.
Feedback, Questions, & Concerns
Feedback, questions, or concerns? The core DataHub team wants to hear from you! For any inquiries, you can find us hanging out on Slack.
DataHub
Metadata
Open Source
Modern Data Stack
Tech Deep Dive

NEXT UP

Governing the Kafka Firehose
Kafka’s schema registry and data portal are great, but without a way to actually enforce schema standards across all your upstream apps and services, data breakages are still going to happen. Just as important, without insight into who or what depends on this data, you can’t contain the damage. And, as data teams know, Kafka data breakages almost always cascade far and wide downstream—wrecking not just data pipelines, and not just business-critical products and services, but also any reports, dashboards, or operational analytics that depend on upstream Kafka data.

When Data Quality Fires Break Out, You're Always First to Know with Acryl Observe
Acryl Observe is a complete observability solution offered by Acryl Cloud. It helps you detect data quality issues as soon as they happen so you can address them proactively, rather than waiting for them to impact your business’ operations and services. And it integrates seamlessly with all data warehouses—including Snowflake, BigQuery, Redshift, and Databricks. But Acryl Observe is more than just detection. When data breakages do inevitably occur, it gives you everything you need to assess impact, debug, and resolve them fast; notifying all the right people with real-time status updates along the way.
John Joyce
2024-04-23

Five Signs You Need a Unified Data Observability Solution
A data observability tool is like loss-prevention for your data ecosystem, equipping you with the tools you need to proactively identify and extinguish data quality fires before they can erupt into towering infernos. Damage control is key, because upstream failures almost always have cascading downstream effects—breaking KPIs, reports, and dashboards, along with the business products and services these support and enable. When data quality fires become routine, trust is eroded. Stakeholders no longer trust their reports, dashboards, and analytics, jeopardizing the data-driven culture you’ve worked so hard to nurture
John Joyce
2024-04-17