
The 3 Must-Haves of Metadata Management — Part 2
Metadata Management
Open Source
Data Engineering
Best Practices
DataHub


Metadata Management
Open Source
Data Engineering
Best Practices
DataHub
I’m back with another post on metadata must-haves. Last time, I spoke about Metadata 360 and how it combines logical and technical metadata to manage and use metadata effectively. Today, I’m going to focus on a metadata management principle that I’m personally very, very enthusiastic about: Shift Left.
In principle, Shift Left refers to the practice of declaring and emitting metadata at the source, i.e., where the data is generated. This means that instead of treating metadata as an afterthought (all too often the case!) and annotating it later, we emit metadata right where the code is managed and maintained.
This is important for two reasons:
1) It helps us meet developers or teams where they are — instead of forcing new processes or workflows upon them for the sake of documentation.


2) It has a significant role to play in understanding the downstream implications of any changes or identifying breaking changes.


DataHub and Shift Left
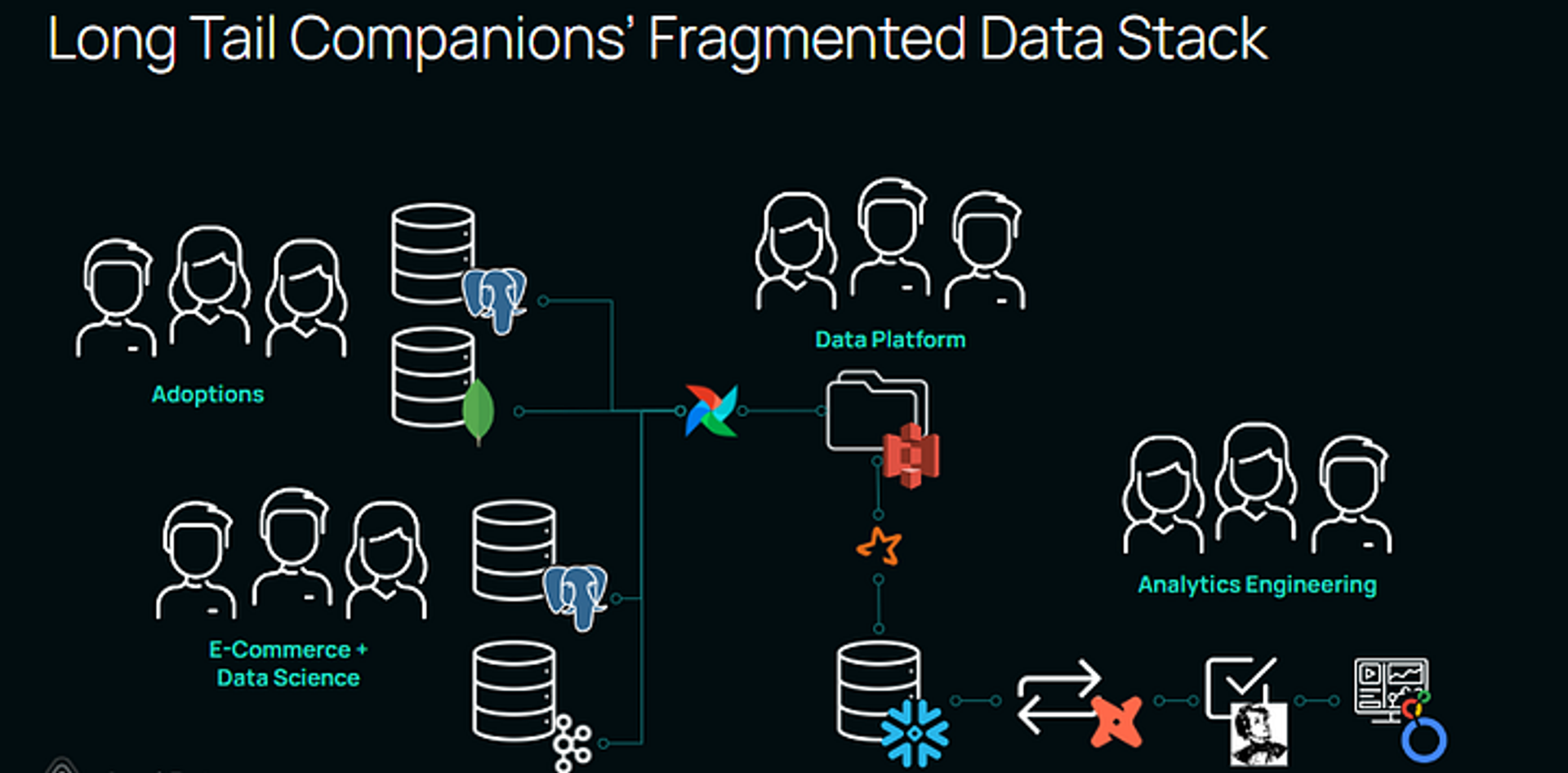
To understand this, let’s go back to the example of our friends at Long Tail Companions (LTC) that we spoke about in Part 1. (Missed it? Read it here: The 3 Must-Haves of Metadata Management — Part 1)

Shift Left: Metadata in Code
The LTC Team can use meta blocks within the schema YAML for their dbt model to define metadata at source, as shown below.
With this, the LTC Team can define a fully customizable meta block to capture the most critical metadata next to the code that generates the data, assigning:
- asset ownership
- model maturity status (Production or Development, for instance)
- PII status
- domain (common in organizations that are adopting Data Mesh)

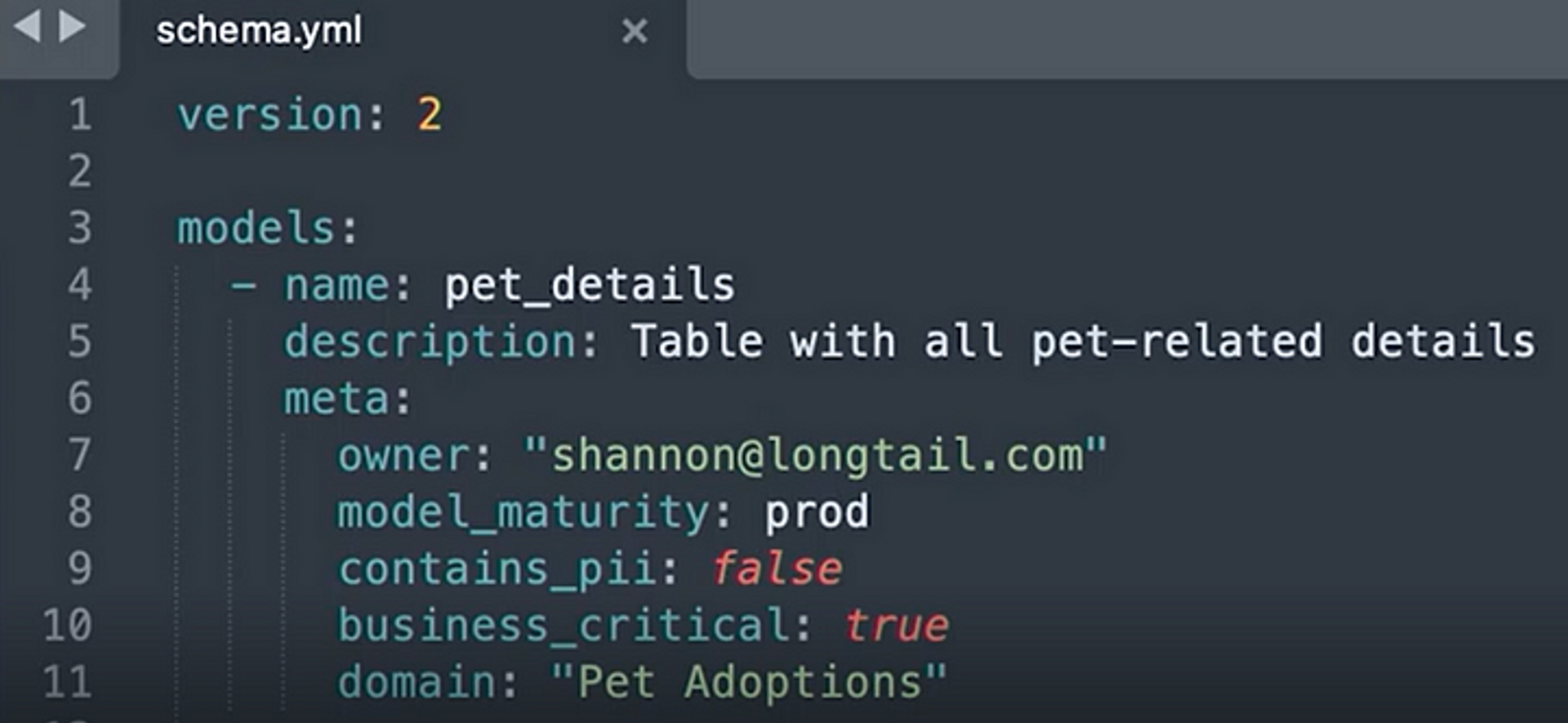
This way, the owner of a dbt model, can focus on building out the model, assigning it to different domains, and assigning tags to it — all within code.
And the data catalog — DataHub in this example — can bubble it all up with all the associated context.

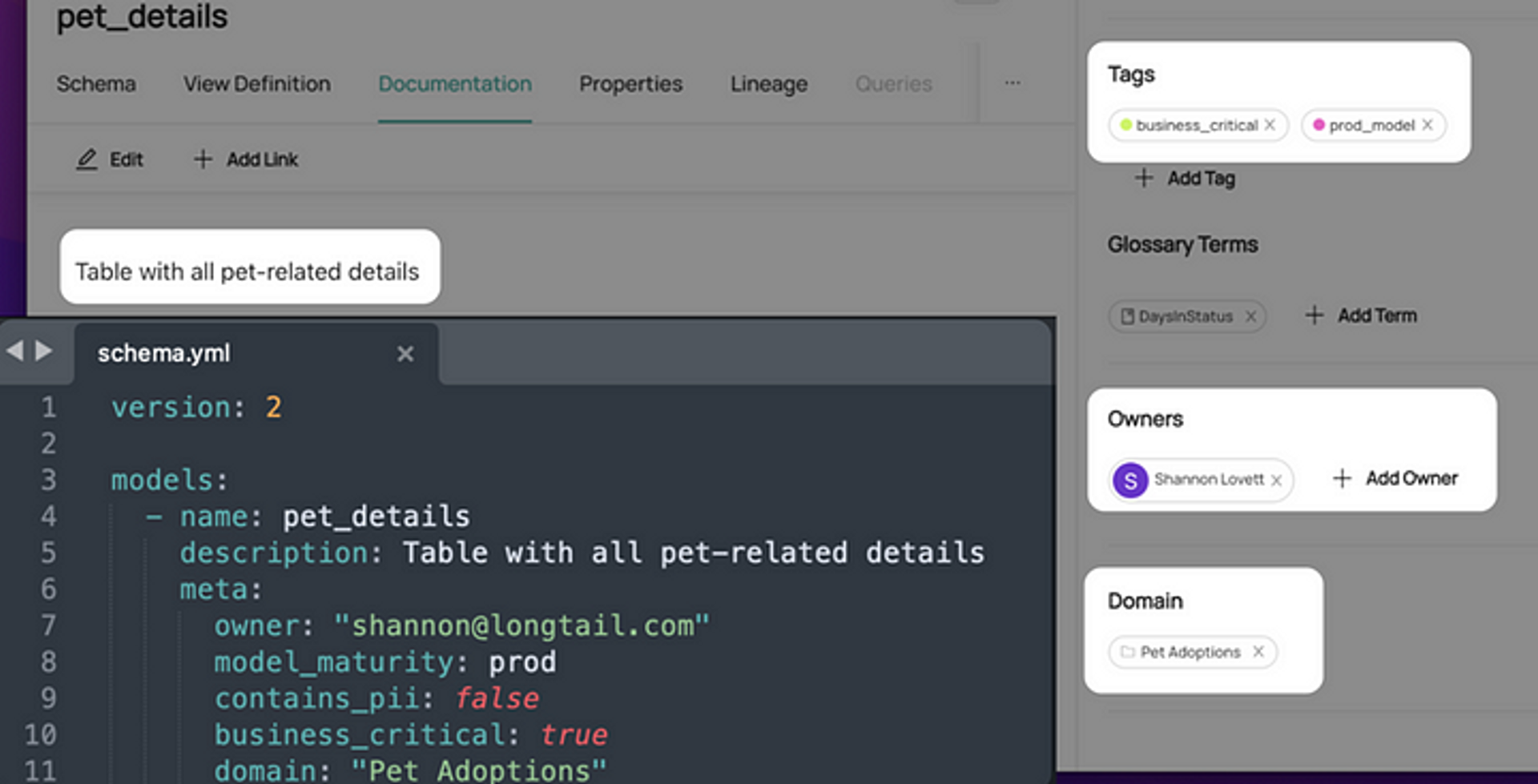
How DataHub surfaces metadata added at source in its UI
Let’s also look at another application of Shift Left — this time, with LTC’s Ecommerce team that works with Kafka and Protobuf.
The team can simply annotate their schema while adding it to their datasets (or topics as they are called in Kafka).


In the example of the Kafka Search Event above, you can see a few additional annotations marked as options, such as the
- classification option (Classification.Sensitive)
- team option (Ecommerce)
- IP address field with a sensitive classification
This approach ensures that schema annotations live alongside Protobuf schemas — putting business context and business metadata in line with their schemas.

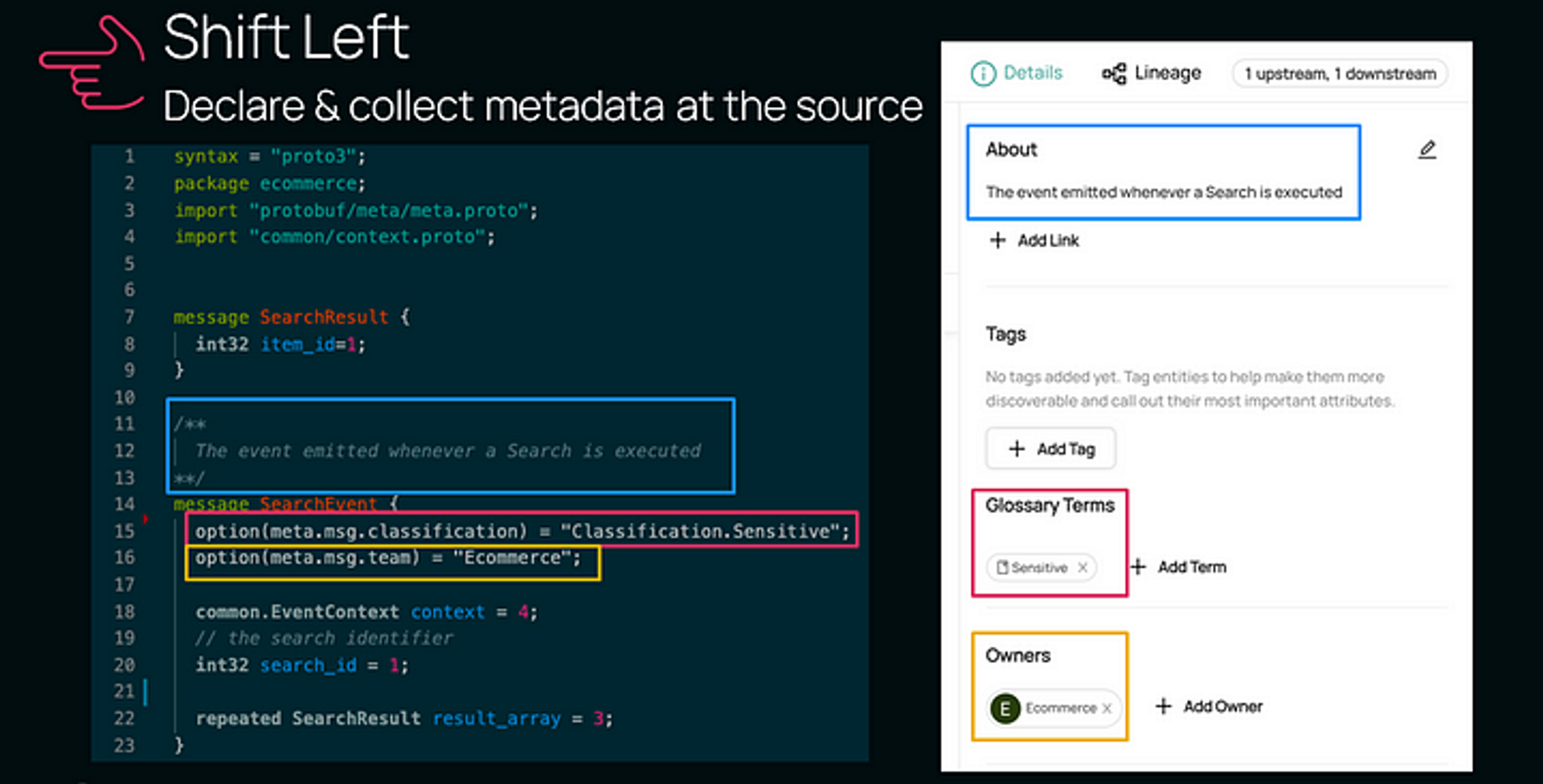
And on DataHub, searching for the Search Event surfaces individual elements from those schemas directly mapped into tags, terms, or documentation.
Additionally, the team can use schema linters to validate if the schema has the required annotations before pushing metadata artifacts to DataHub via their CI/CD pipelines.
I hope these examples using dbt and Kafka explain how the Shift Left principle can be tailored to different teams’ tools and development patterns — while ensuring the same discovery/surface experience within DataHub.
Shift Left for Impact analysis
Another important aspect of shifting left is moving focus leftwards towards production systems to understand the downstream impact.
And here’s why emitting metadata at source helps: it ensures that you have a robust knowledge graph with a reliable view of interdependencies and how different components work together. The correct data catalog can help you use this rich metadata for impact analysis.
DataHub’s Lineage Impact Analysis feature offers the ability to get a snapshot view of all the resources so individuals can proactively reach out to folks for conversations around breaking changes.

Dependency Impact Analysis in DataHub
You can look at the lineage, understand dependencies, and even export all this information in a CSV.
Need any help understanding how you can use impact analysis in DataHub? Ask us on our Slack channel or check out the DataHub Lineage Impact Analysis feature guide.
That’s it from me for now…oh, and one last thing before I go, do check out Shirshanka’s excellent blog post on Shifting Left on Governance.
Connect with DataHub
Metadata Management
Open Source
Data Engineering
Best Practices
DataHub

NEXT UP

Governing the Kafka Firehose
Kafka’s schema registry and data portal are great, but without a way to actually enforce schema standards across all your upstream apps and services, data breakages are still going to happen. Just as important, without insight into who or what depends on this data, you can’t contain the damage. And, as data teams know, Kafka data breakages almost always cascade far and wide downstream—wrecking not just data pipelines, and not just business-critical products and services, but also any reports, dashboards, or operational analytics that depend on upstream Kafka data.

When Data Quality Fires Break Out, You're Always First to Know with Acryl Observe
Acryl Observe is a complete observability solution offered by Acryl Cloud. It helps you detect data quality issues as soon as they happen so you can address them proactively, rather than waiting for them to impact your business’ operations and services. And it integrates seamlessly with all data warehouses—including Snowflake, BigQuery, Redshift, and Databricks. But Acryl Observe is more than just detection. When data breakages do inevitably occur, it gives you everything you need to assess impact, debug, and resolve them fast; notifying all the right people with real-time status updates along the way.


John Joyce
2024-04-23

Five Signs You Need a Unified Data Observability Solution
A data observability tool is like loss-prevention for your data ecosystem, equipping you with the tools you need to proactively identify and extinguish data quality fires before they can erupt into towering infernos. Damage control is key, because upstream failures almost always have cascading downstream effects—breaking KPIs, reports, and dashboards, along with the business products and services these support and enable. When data quality fires become routine, trust is eroded. Stakeholders no longer trust their reports, dashboards, and analytics, jeopardizing the data-driven culture you’ve worked so hard to nurture
John Joyce
2024-04-17