
Automating Propagations with DataHub and DataHub-Tools
DataHub
Dbt
Metadata


DataHub
Dbt
Metadata
The propagating of metadata, tags, and owners outside of a DataHub dataset ingestion can be made easy.
At Notion, data powers our business decision-making and our product itself. Therefore, it is essential for us to (a) understand what data in our warehouse is business critical and (b) ensure our critical data is built off of reliable sources. Without this understanding, we cannot effectively respond to incidents or know where to focus our reliability efforts. This would mean our customers and internal stakeholders would lose faith in our data.
We rely on Acryl Datahub to gain these insights and ensure our critical data is reliable. Datahub is the #1 open-source data catalog for data discovery and modern governance. Acryl’s SaaS product takes DataHub to the next level through automation and emphasis on time-to-value. In this post, we will discuss an integration we have built on top of DataHub to make sure our business-critical datasets are always properly labeled so we are able to respond to incidents with the most up to date information.
The Problem
At Notion, we use a complicated formula that calculates who should own datasets and how these datasets should be triaged should their workflows fail. When we excitedly signed up with Acryl Data we were faced with the challenge of migrating away from our manual processes of tagging and annotating our tables within DataHub. We were able to automate using DataHub’s robust API which solves the problem of managing entities outside of their ingestion. However, we were met with a lot of boilerplate, so we wrote and open-sourced a small Python package that wraps the API’s endpoints.
Let’s look at a simplified example of how we used the package to solve the problem…
Say we have some metadata boolean flags that describe how a dataset is used:
- is_exposed_externally
- is_used_to_drive_company_metrics
We want to use those flags to decide the right triage priority and owners for a given table.

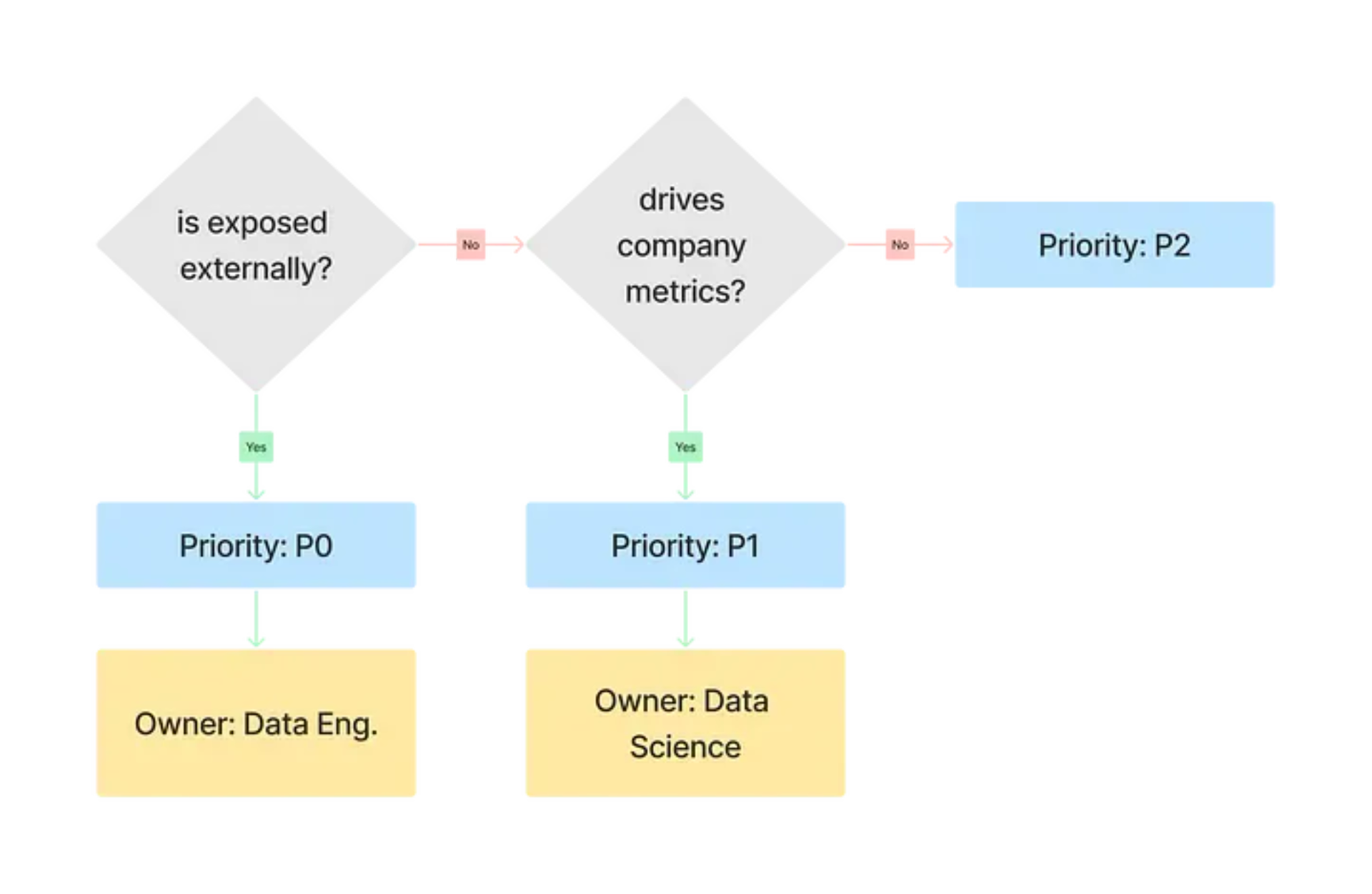
- If is_exposed_externally is TRUE then assign the highest priority, “P0” and assign the data engineering team as the technical owner
- If is_used_to_drive_company_metrics is TRUE then it’s still important, but a bit less critical so “P1” and our best owner would be the data science team.
- Otherwise, we’ll give the lowest priority P2, and not assign an owner.
But we also need to consider any downstream tables that have a higher priority so the first step is to propagate metadata by inspecting the lineage. The best place to modify metadata is during ingestion, so we’ll need a transformer to do that work for us.
A full example of how to add a metadata transformer can be found as an example in the datahub-tools repository, but the heart of the work is summarized below.
Part 1: Metadata Propagation
A transformer is a custom class that is called during the ingest of your data into DataHub.
class MyPropertiesResolver(AddDatasetPropertiesResolverBase):
def get_properties_to_add(self, entity_urn: str) -> dict[str, str]:
# returns a dictionary of metadata that should be included during
# ingest for the givent entity_run
return {}Steps that we will need to take to fill out this class:
- Get our resources (A resource is a table of data generated from SQL and is synonymous with a model or a DataHub dataset entity)
- Propagate metadata from downstream resources
- Provide a lookup that returns the metadata for a given DataHub entity URN.
We will combine all of these steps into one function that we can call in the constructor of the class.
- Get Resources
Our metadata are stored within our DBT resources, so the first step is to fetch them all from a generated manifest.json. (For readers that are not familiar with DBT, the manifest contains all of the information on how to run the SQL for a given table, including all of its dependencies and metadata). Fortunately, the datahub-tools package has a convenient function to do this work for us.
from datahub_tools.dbt import extract_dbt_resources
resources_by_unique_id: dict[str, dict] = extract_dbt_resources(
manifest_file='/path/to/your/manifest.json'
)2. Propagate Metadata
Again, the datahub-tools package can help significantly as it offers a convenience function that provides all downstream and upstream resources for a given resource.
from datahub_tools.dbt import get_dbt_dependencies
dependencies: dict[str, ModelDependency] = get_dbt_dependencies(
dbt_resources_by_unique_id=resources_by_unique_id
)We can now propagate the metadata along:
for unique_id, resource in resources_by_unique_id.items():
upstream_unique_ids: set[str] = dependencies[unique_id].get_all_upstream()
# note that this is a custom metadata store that we added to our DBT
resource_metadata = resource['config']['notion_metadata']
for upstream_unique_id in upstream_unique_ids:
upstream_resource = resources_by_unique_id[upstream_unique_id]
upstream_metadata = upstream_resource['config']['notion_metadata']
propagated_metadata = propagate(upstream_metadata, resource_metadata)
upstream_resource['config']['notion_metadata'] = propagated_metadataWhere the propagation logic is just combining the two dictionaries of booleans with or:
propagate(left: dict[str, bool], right: dict[str, bool]) -> dict[str, bool]:
return {
'is_exposed_externally':
left['is_exposed_externally'] or right['is_exposed_externally'],
'is_used_to_drive_company_metrics':
left['is_used_to_drive_company_metrics'
or right['is_used_to_drive_company_metrics'
}This strategy of using or ensures that every resource has True set for a metadata entry if it or any of its downstream dependencies are set to True .
3. Map our Resources to DataHub Entities
We have our propagated metadata all within resources_by_unique_id but this maps a DBT unique id to the resource when DataHub uses the table name. (A DBT unique id is of the form type.table_name such as model.my_table whereas DataHub uses the table’s storage location, such as production.my_table ).
metadata_by_table_name: dict[str, dict] = {
x['name'], x['config']['notion_metadata']
for x in resources_by_unique_id.values()
}Putting it all together into the Transformer class:
import datahub.emitter.mce_builder as builder
from datahub.ingestion.transformer.add_dataset_properties import (
AddDatasetPropertiesResolverBase,
)
from datahub_tools.dbt import (
extract_dbt_resources, get_dbt_dependencies, ModelDependency,
)
class MyPropertiesResolver(AddDatasetPropertiesResolverBase):
def __init__(self):
super().__init__()
resources_by_unique_id: dict[str, dict] = extract_dbt_resources(
manifest_file='/path/to/your/manifest.json'
)
dependencies: dict[str, ModelDependency] = get_dbt_dependencies(
dbt_resources_by_unique_id=resources_by_unique_id
)
# propoagate metadata
for unique_id, resource in resources_by_unique_id.items():
upstream_unique_ids: set[str] = dependencies[unique_id].get_all_upstream()
# note that this is a custom metadata store that we added to our DBT
resource_metadata = resource['config']['notion_metadata']
for upstream_unique_id in upstream_unique_ids:
upstream_resource = resources_by_unique_id[upstream_unique_id]
upstream_metadata = upstream_resource['config']['notion_metadata']
propagated_metadata = propagate(upstream_metadata, resource_metadata)
upstream_resource['config']['notion_metadata'] = propagated_metadata
self.metadata_by_table_name: dict[str, dict] = {
x['name'], x['config']['notion_metadata']
for x in resources_by_unique_id.values()
}
def get_properties_to_add(self, entity_urn: str) -> dict[str, str]:
# returns a dictionary of metadata that should be included during
# ingest for the givent entity_run
dataset_key: DatasetKeyClass = builder.dataset_urn_to_key(entity_urn)
return self.metadata_by_table_name.get(dataset_key, {})There is a bit of additional boilerplate required to add this transformer to your ingest, which can be found in the official documentation, but you can now transform your metadata entries during data ingest.
Part 2: Tags and Owners
Now that we have propagated and ingested metadata, we can calculate the appropriate owner and priority.
We first define how we will associate an owner and priority. In the interest of brevity, the calculation of the owner and priority were combined into one function (despite not being best practice to do so).
import datahub.emitter.mce_builder as builder
def metadata_to_priority_and_owner(metadata: dict[str, str]) -> tuple[str, str | None]:
def _get_metadata(key: str) -> bool | None:
value = metadata.get(key)
return value.lower().strip() == "true" if value else None
is_exposed_externally = _get_metadata('is_exposed_externally')
is_used_to_drive_company_metrics = _get_metadata(
'is_used_to_drive_company_metrics'
)
if is_exposed_externally:
priority_tag_urn = builder.make_tag_urn("P0")
group_owner_urn = builder.make_group_urn("data_engineering")
elif is_used_to_drive_company_metrics:
priority_tag_urn = builder.make_tag_urn("P1")
group_owner_urn = builder.make_group_urn("data_science")
else:
priority = builder.make_tag_urn("P2")
group_owner_urn = None
return priority_tag_urn, ownerWe now just have to fetch the metadata, pass it to the above function, and then set the owners and tags using the DataHub API. Fortunately, the datahub-tools makes this process easier as well.
from datahub_tools.client import get_datahub_entities, DHEntity
entities: list[DHEntity] = get_datahub_entities()The API allows batch setting/removing of tags/owners, and so we’ll group our changes as a list of entities that need each operation, reducing the overall number of calls that need to be made.
import datahub.emitter.mce_builder as builder
add_tags: [str, list[DHEntity]] = {}
rem_tags: [str, list[DHEntity]] = {}
for dh_entity in entities:
# priorities are P0, P1, or P2
# owners are "data_engineering", "data_science", or None
calculated_priority, calculated_owner = metadata_to_priority(dh_entity.metadata)
existing_priority: str | None = dh_entity.get_priority()
existing_owner: str | None = dh_entity.get_owner()
# Remove priority if the new priority is None or is different
# Add the priority if the existing priority is None or is different
# (don't do anything if both are the same, including both being None)
if calculated_priority != existing_priority:
if existing_priority:
existing_priority_urn = builder.make_tag_urn(existing_priority)
entities = rem_tags.get(existing_priority_urn, [])
entities.append(dh_entity)
if existing_priority_urn not in rem_tags:
rem_tags[existing_priority_urn] = entities
if calculated_priority:
new_priority_urn = builder.make_tag_urn(calculated_priority)
entities = add_tags.get(new_priority_urn, [])
entities.append(dh_entity)
if new_priority_urn not in add_tags:
add_tags[new_priority_urn] = entities
# and similarly for owners
...Finally, we set/remove tags using functions from datahub-tools.
from datahub_tools.client import remove_tags, set_tags
for tag_urn, entities in rem_tags.items():
remove_tags(tag_urns=tag_urn, resource_urns=[x.urn for x in entities])
for tag_urn, entities in add_tags.items():
set_tags(tag_urns=tag_urn, resource_urns=[x.urn for x in entities])
# and similaryly for owners, using the functions set_group_owner and
# remove_owners from datahub_toolsAbove, we have shown how to inject metadata into our resources during the ingestion to DataHub. We also demonstrated how to pull that metadata back down, and then calculate then set owner and priority tags. To make all of it easier, there was frequent use of the open-source package datahub-tools.
We hope you found this demonstration useful and best of luck in your data cataloging!
DataHub
Dbt
Metadata

NEXT UP

Governing the Kafka Firehose
Kafka’s schema registry and data portal are great, but without a way to actually enforce schema standards across all your upstream apps and services, data breakages are still going to happen. Just as important, without insight into who or what depends on this data, you can’t contain the damage. And, as data teams know, Kafka data breakages almost always cascade far and wide downstream—wrecking not just data pipelines, and not just business-critical products and services, but also any reports, dashboards, or operational analytics that depend on upstream Kafka data.

When Data Quality Fires Break Out, You're Always First to Know with Acryl Observe
Acryl Observe is a complete observability solution offered by Acryl Cloud. It helps you detect data quality issues as soon as they happen so you can address them proactively, rather than waiting for them to impact your business’ operations and services. And it integrates seamlessly with all data warehouses—including Snowflake, BigQuery, Redshift, and Databricks. But Acryl Observe is more than just detection. When data breakages do inevitably occur, it gives you everything you need to assess impact, debug, and resolve them fast; notifying all the right people with real-time status updates along the way.


John Joyce
2024-04-23

Five Signs You Need a Unified Data Observability Solution
A data observability tool is like loss-prevention for your data ecosystem, equipping you with the tools you need to proactively identify and extinguish data quality fires before they can erupt into towering infernos. Damage control is key, because upstream failures almost always have cascading downstream effects—breaking KPIs, reports, and dashboards, along with the business products and services these support and enable. When data quality fires become routine, trust is eroded. Stakeholders no longer trust their reports, dashboards, and analytics, jeopardizing the data-driven culture you’ve worked so hard to nurture
John Joyce
2024-04-17